Last week, we tasked Kyle from our Research and Development team with covering some common themes discussed at Black Hat and DEF CON. We want to bring these issues to both the security community that was in Vegas at the cons and those who kept an eye on the action from the outside.
“Deep learning” was a phrase that came up many times during Black Hat. It seems to have quickly risen to relative prominence, and it certainly merits discussion: the broad field of machine learning often can be and is applied, and developments in the field have definite potential to help the security field make better sense of the data.
In this post, we’re going to discuss two talks from Black Hat 2015 regarding applications of deep learning after covering some background on the subject matter..
Deep Learning Background
Deep learning is based on neural networks, so let’s take a tour of some background on machine learning, in roughly the same sense that I once toured Connecticut while on I-684.
The fundamental unit of neural networks is the perceptron, contrary to literally everyone’s intuition that it’d be called a “neuron.” Perceptrons are just like neurons: pretty stupid on their own, but powerful when linked. Each perceptron takes numerical inputs, performs some algebra, and then returns 1 if the result is above some threshold, and 0 if not.
Perceptrons are arranged in layers where each perceptron sends its result to the ones in the next layer, like in the following image:
Single-hidden-layer neural network:
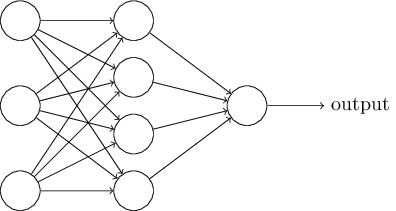
So, what’s “deep learning” then? Oh, you mean besides a buzzword? The definition that often was used in the talks this week was “neural nets with at least two hidden layers but often closer to 20 than 2.” The intuition is identical - you just keep adding layers, which can enable better results for complex models when the relationship between a factor, the other factors, and the output is more complicated than what a single hidden layer can “understand.”
Multiple-hidden-layer (“deep”) neural network:
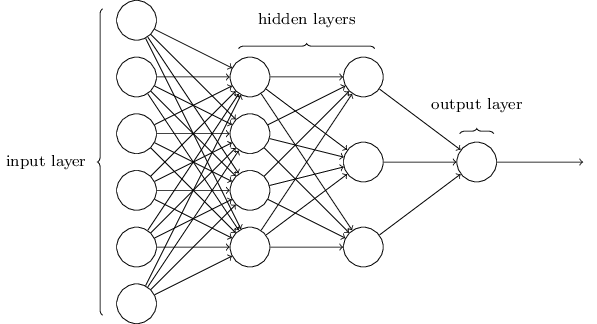
Okay, hopefully you feel more enlightened than confused at this point.
The Actual Talks
The Applications of Deep Learning on Traffic Identification
At Black Hat this year, Zhanyi Wang and Chuanming Huang of Qihoo 360 Technology, a Chinese security company and antivirus vendor, discussed the application of this deep learning workflow to traffic identification.
Right now, the first piece of data we use to identify traffic is port number, as most services on the Internet operate on a well-known port, like 80 for HTTP or 22 for SSH. Of course, that port can be changed for nearly all software, at the possible expense of ease of access.
Beyond just port-based classification, a common method is pattern matching: if your payload contains “HTTP/1.1” near the start, it’s pretty clear that you’re almost certainly looking at an HTTP packet. If we want to generalize this, however, series of rules and patterns often break down due to protocol extensions, new protocols and ambiguities if rules aren’t specific and accurate.
These researchers tackled the question of generalizing port identification by feeding labeled packet flows into a deep learning model. They reported an average accuracy on test data of 97.9%, with protocols like SMB and NetBIOS being classified 100% correctly. An interesting extension of this used training data labeled with the source application to detect not just which protocol (or even just disregarding the question of protocol) but which application was likely the sender. This test yielded 96.3% precision, which seems to be a very reasonable rate of detection, though the presenters didn’t present any sort of comparison.
It’s also unclear if this approach could successfully distinguish between applications of the same type, e.g., Chrome, Firefox, and Internet Explorer. This project feels like a reasonable application of deep learning, though, without results from more traditional methods, I’m not comfortable endorsing the approach outright.
View slides from the presentation.
Deep Learning on Disassembly Data
Andrew Davis and Matt Wolff, anti-malware researchers from Cylance took the principles of deep learning and applied them to the disassembly of binaries.
They did this by disassembling programs to the per-instruction bytecode, padding each out to 64 bits (since amd64 instructions are variable length, up to 64 bits), and making an image by plotting each bit as either black or white, with one instruction per row in the image.
They then took these images and fed them into a convolutional neural network, which is a variant of a neutral network that is often used for image and video recognition. It’s well-suited for analyses that depend on processing small parts of an image at a time, similar to the human brain.
Taking the resulting model, which had roughly 90% precision, the presenters “interrogated” it to reveal which code segments were the most useful in determining maliciousness.
The talk ended at this point, although it’s clear there’s future work to be done that involves de-imagifying the code to identify and understand more about the deciding chunks and patterns of code. Knowing what makes or breaks the goodness of a binary would certainly be useful, both for efficient testing and informing malware researchers.
View slides from the presentation.
The Opinion
First and foremost, “deep learning” as a topic certainly seems to be primarily a rebranding of the concept of neural networks, which makes the relative prevalence of deep-learning talks eye-roll-worthy.
The cynics among us would take this opportunity to remind everyone of the (possibly apocryphal) classic tale of the US’s neural-network-based tank detector as a warning that the meaning of weights and thresholds in neural networks is largely opaque upon inspection, and, thus, unintentional biases in your training data may very well go undetected. This is complicated by the fact that the publicly available malware datasets are often dated, and, for what there is, there aren’t many useful corpuses of known-good software.
In addition, neutral networks, just like any other machine learning technique, aren’t always the best tool for the job. They may be the right tool here, but it’s impossible to quantifiably say that without evaluating even one other paradigm, which neither of these talks did. To my mildly trained eye, there weren’t convincing arguments for only considering neural nets.
There certainly is a contribution to the state of the art if neural nets haven’t been applied to these problems, but those aren’t answers to the questions we’re actually asking on the ground. These are ones like “Which machine learning techniques work best for classifying binary files into malicious vs. benign?” and these solve actual problems.
To be fair, knowing the performance of neural networks is a precursor to being able to answer that question, but there’s no indication that anyone’s moving in that direction after finding the first machine learning (ML) model that works reasonably well in their domain of concern.
The art and science of these fields could progress much faster if teams working on just one ML application to one problem focused on the higher-order question and evaluated a breadth of approaches to be able to say something concrete and generalizable rather than assorted surveys of performance with different models and different data sets.